참고 자료
DB 정규화 (normalization)
데이터 중복과 insertion, update, deletion anomaly를 최소화하기 위해
일련의 normal forms(NF)에 따라 relational DB를 구성하는 과정
Normal forms(NF)
정규화 되기 위해 준수해야 하는 몇 가지 rule들이 있는데
이 각각의 rule을 normal from(NF)이라고 부른다
참고
해당 내용은 FD에 대한 이해가 먼저 필요하다 모른다면 아래 링크를 참고하자
https://20240228.tistory.com/413
[DB] functional dependency 함수 종속
참고 자료 유투브 쉬운코드 functional dependency 함수 종속Functional Dependency (FD)한 테이블에 있는 두 개의 attribute(s) 집합 사이의 제약EMPLOYEE 테이블 집합 X: empl_id집합 Y: empl_name, birth_date, position, salary
20240228.tistory.com
DB 정규화 과정

처음부터 순차적으로 진행하며 normal form을 만족하지 못하면 만족하도록 테이블 구조를 조정한다
앞 단계를 만족해야 다음 단계로 진행할 수 있다
1NF ~ BCNF: FD, KEY 만으로 정의되는 normal forms
3NF까지 도달하면 정규화 됐다고 말하기도 함
보통 실무에서는 3NF / BCNF 까지 진행 (많이 해도 4NF 정도까지만 진행)
DB 정규화 과정 예제

임직원의 월급 계좌를 관리하는 테이블
bank_name: 월급 계좌의 은행은 국민은행 OR 우리은행
한 임직원이 하나 이상의 월급 계좌를 등록하고 월급 비율(ratio)을 조정할 수 있다
계좌마다 등급(class)이 있다 (국민: STAR → PRESTIGE → LOYAL, 우리: BRONZE → SILVER → GOLD)
한 계좌는 하나 이상의 현금 카드와 연동될 수 있다
KEY
SUPER KEY : table에서 tuple들을 unique하게 식별할 수 있는 attributes set
(candidate) KEY: 어느 한 attribute라도 제거하면 unique하게 tuples를 식별할 수 없는 super key
PRIMARY KEY: tuple들을 unique하게 식별하려고 선택된 (candidate) key
prime attribute: 임의의 key에 속하는 attribute
non-prime attribute: 어떠한 key에도 속하지 않는 attribute
candidate key: {account_id} / {bank_name, account_num}
primary key: {account_id}
prime attribute: account_id, bank_name, account_num
non-prime attribute: class, ratio, empl_id, empl_name, card_id
EMPLOYEE_ACCOUNT 테이블의 FD 표현


{bank_name, account_num} → {account_id, class, ratio, empl_id, empl_name, card_id}
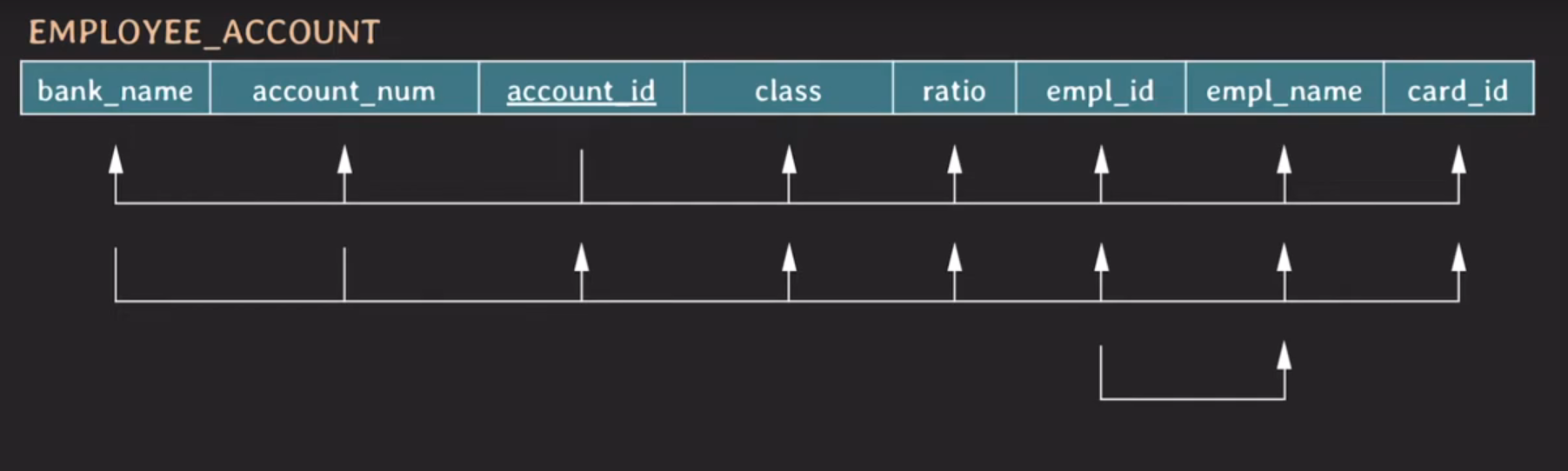
{empl_id} → {empl_name}
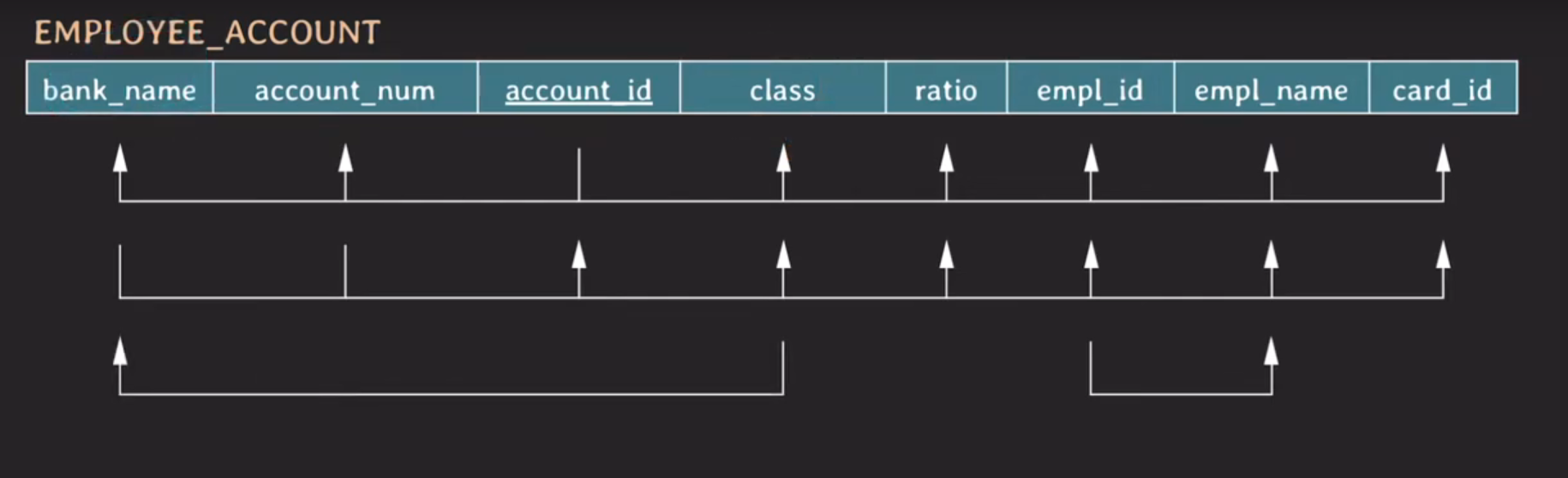
{class} → {bank_name}
각 은행의 등급은 서로 겹치는게 없다. (국민: STAR → PRESTIGE → LOYAL, 우리: BRONZE → SILVER → GOLD)
그래서 class → bank_name은 항상 동일하다
예제 데이터
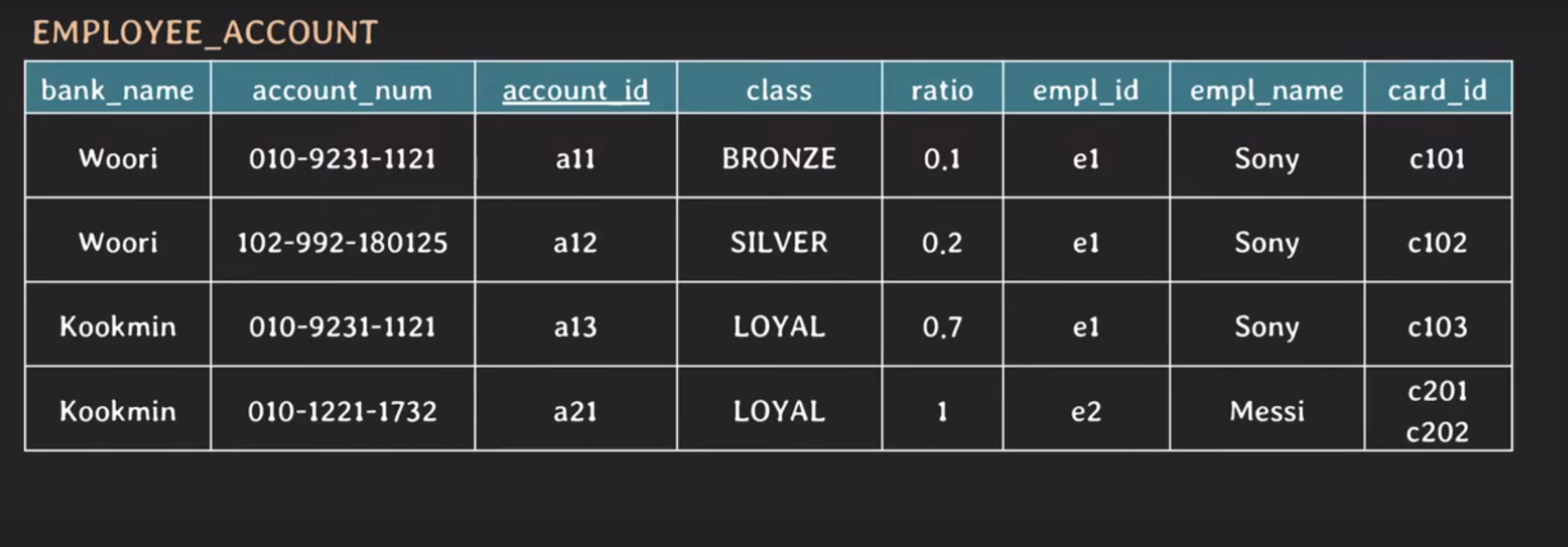
Sony는 총 3개의 계좌로 월급을 각각 0.1 / 0.2 / 0.7 비율로 나눠서 받는다.
Messi는 1개의 계좌에 월급을 다 받는다.
1NF
1NF: attribute의 value는 반드시 나눠질 수 없는 단일한 값이어야 한다
Messi card_id는 현재 1NF를 위한하고 있다.
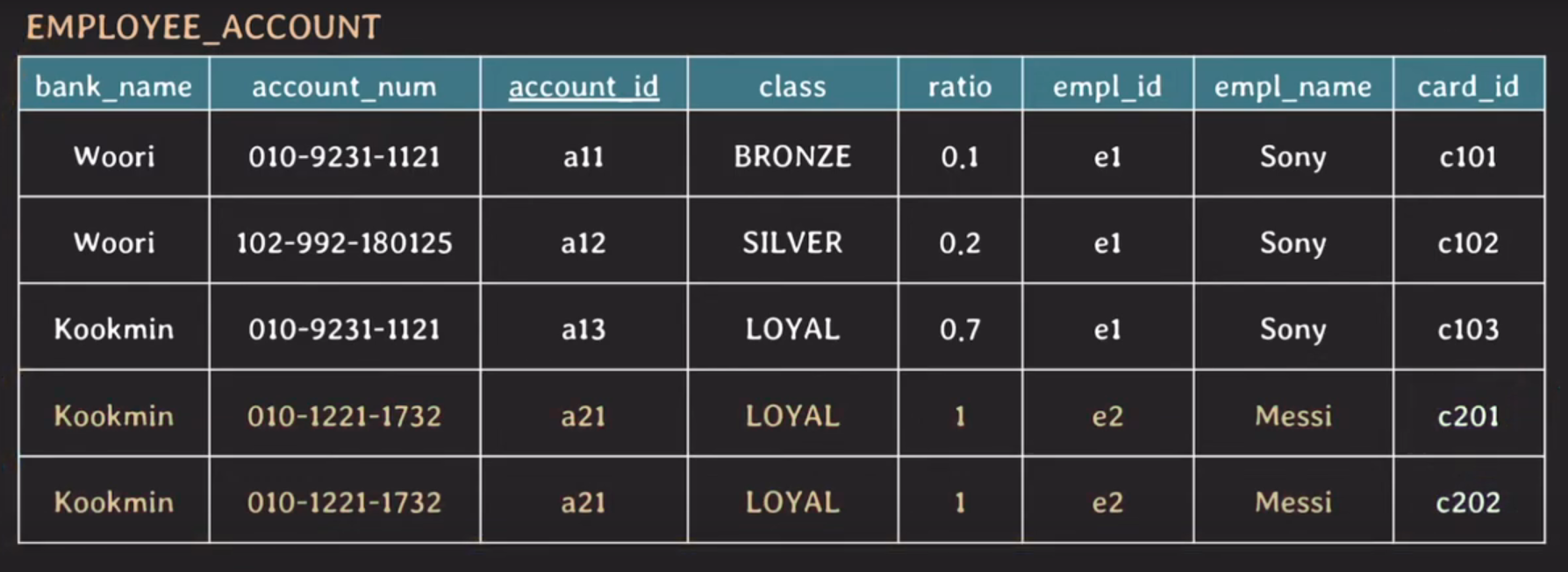
이제 1NF를 만족한다.
하지만 중복 데이터가 생기고 primary key도 변경을 해야 한다
또한 ratio 부분도 이상하다 ratio 합은 1이어야 하는데 합이 2다. (Insertion anomaly)
2NF
2NF: 모든 non-prime attribute는 모든 key에 fully functionally dependent 해야 한다
1NF에서 card_id에 대한 2개 이상의 value 문제를 해결하면서 생긴 문제를 먼저 해결하자
primary key 변경 {account_id} → {account_id, card_id}
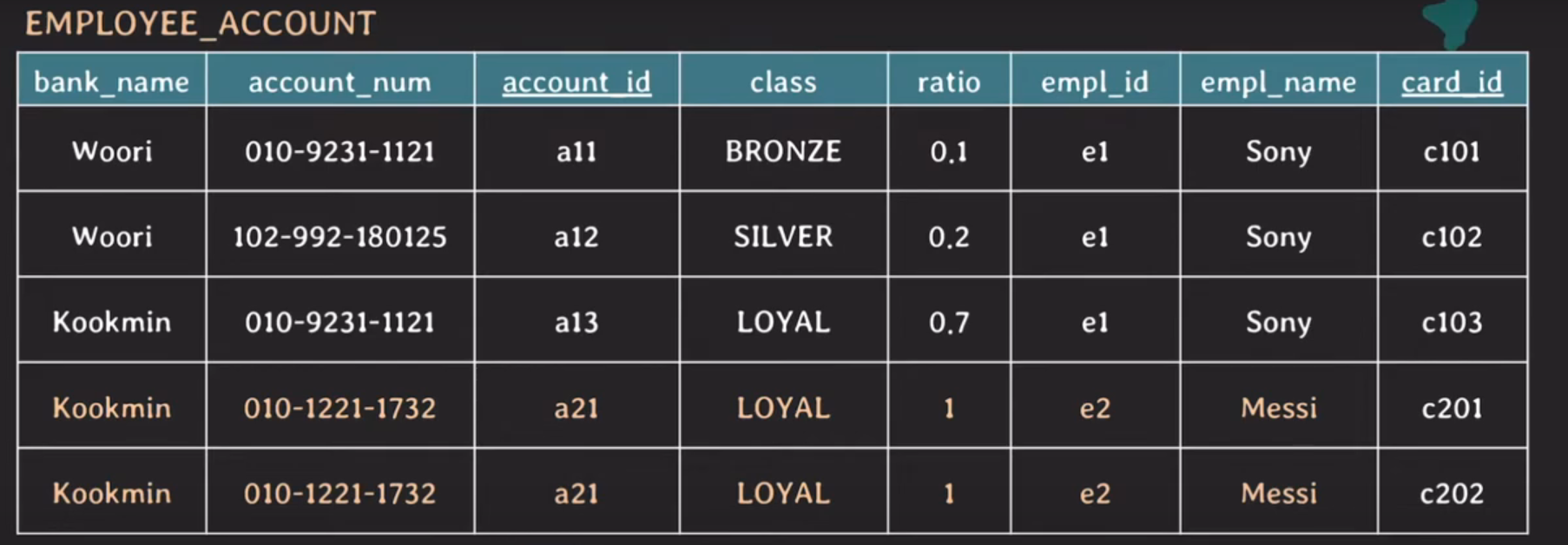
그런데 1NF를 해결하니까 중복 데이터 문제가 보인다. 어떻게 해결할까?
candidate key : {account_id, card_id} , {bank_name, account_num, card_id}
non-prime attributes: class, ratio, empl_id, empl_name
non-prime attributes의 FD 표현

{account_id, card_id} → {class, ratio, empl_id, empl_name}
그런데 함수 종속을 보면 꼭 card_id가 아니어도 account_id 하나로도 non-prime attributes 식별이 가능해 보인다.
즉, 모든 non-prime attributes들이 {account_id, card_id}에 partially dependent 하다

{bank_name, account_num, card_id} → {account_id, class, ratio, empl_id, empl_name}
여기서 모든 non-prime attribute 들이 {bank_name, account_num, card_id}에 partially dependent 하다
즉 현재 non-prime attribute 들이 key에 fully dependent 하지 않아서 생기는 문제다.
2NF 이후
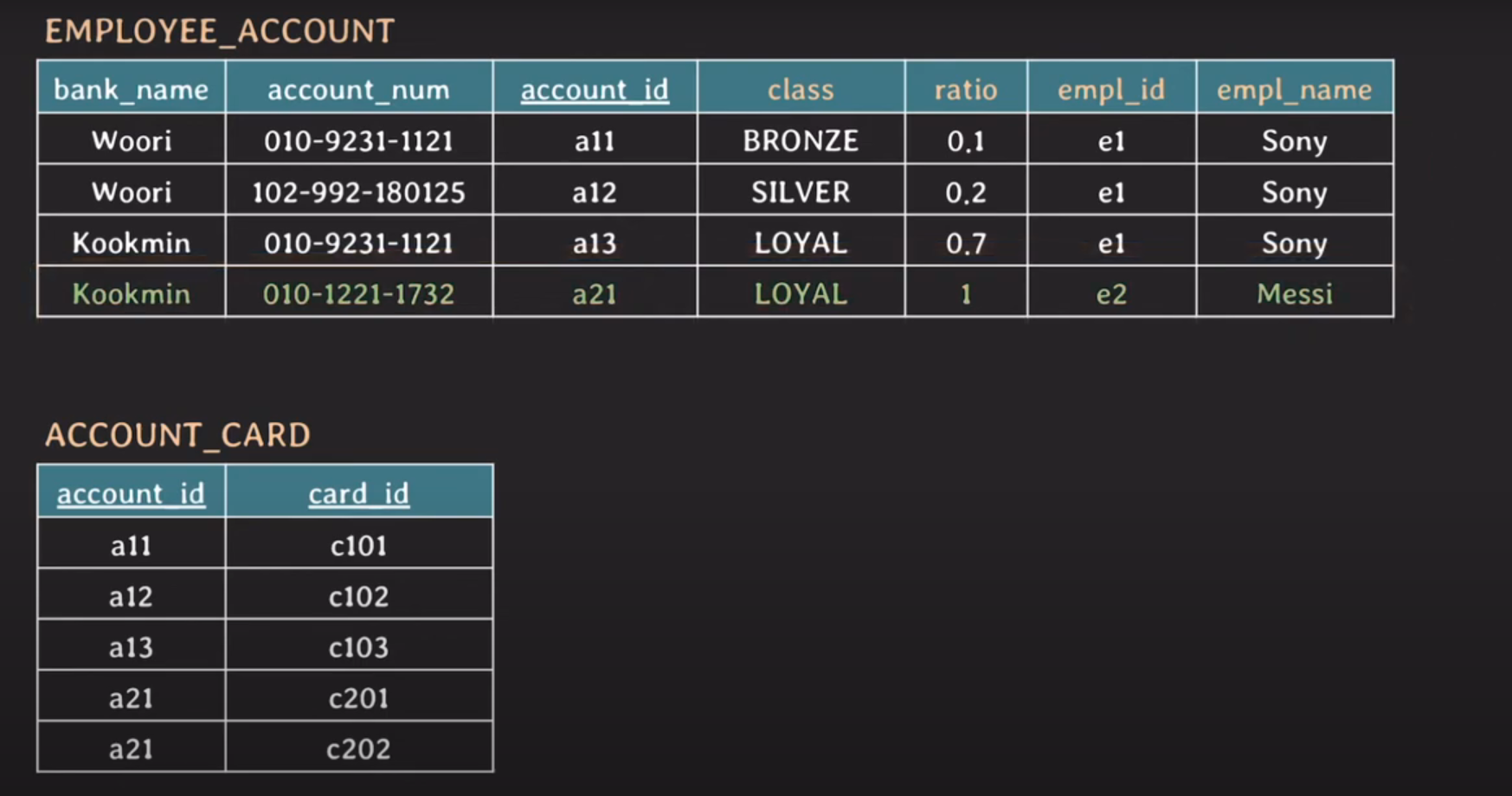
EMPLOYEE_ACCOUNT 테이블의 card_id 부분을 분리했다.
현재 EMPLOYEE 테이블은 2NF를 만족할까?
현재 상황 정리
primary key: account_id 2NF 이후 다시 primary key 또한 account_id로 복구
candidate key: {account_id}, {bank_name, account_num}
non-prime attribute(s): class, ratio, empl_id, empl_name
현재 테이블이 2NF를 만족하는지를 우리가 확인할 부분은
non-prime-attribute 들이 (candidate) key에 fully dependent 하는지만 확인하면 된다.
→ 만족한다
2NF 이후 FD 표현

{account_id} → {empl_id}, {empl_id} → {empl_name}
{acoount_id} → {empl_name}
{bank_name, account_num} → {empl_id}, {empl_id} → {empl_name}
{bank_name, account_num} → {empl_name}
이런 FD를 transitive FD라고 한다.
Transitive FD 정의
if X → Y & Y → Z holds, then X → Z is transitive FD
unless either Y or Z is NOT subset of any key
3NF
3NF: 모든 non-prime attribute는 어떤 key에도 transitively dependent 하면 안된다
즉, non-prime attribute와 non-prime attribute 사이에는 FD가 있으면 안된다
3NF 이후

3NF 까지 진행 이후 전체 테이블들
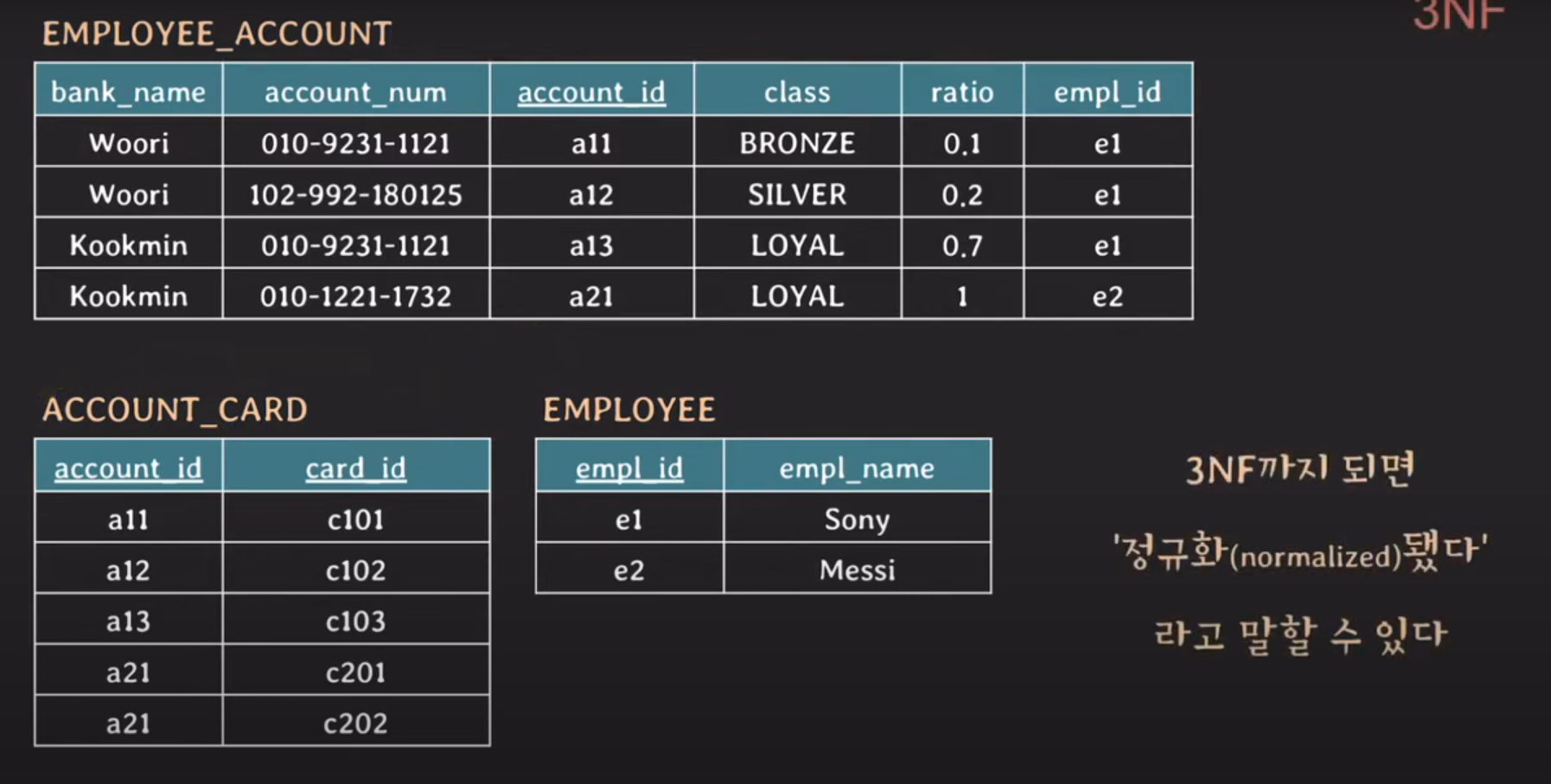
3NF까지 되면 정규화(normalized)됐다 라고 말할 수 있다
BCNF
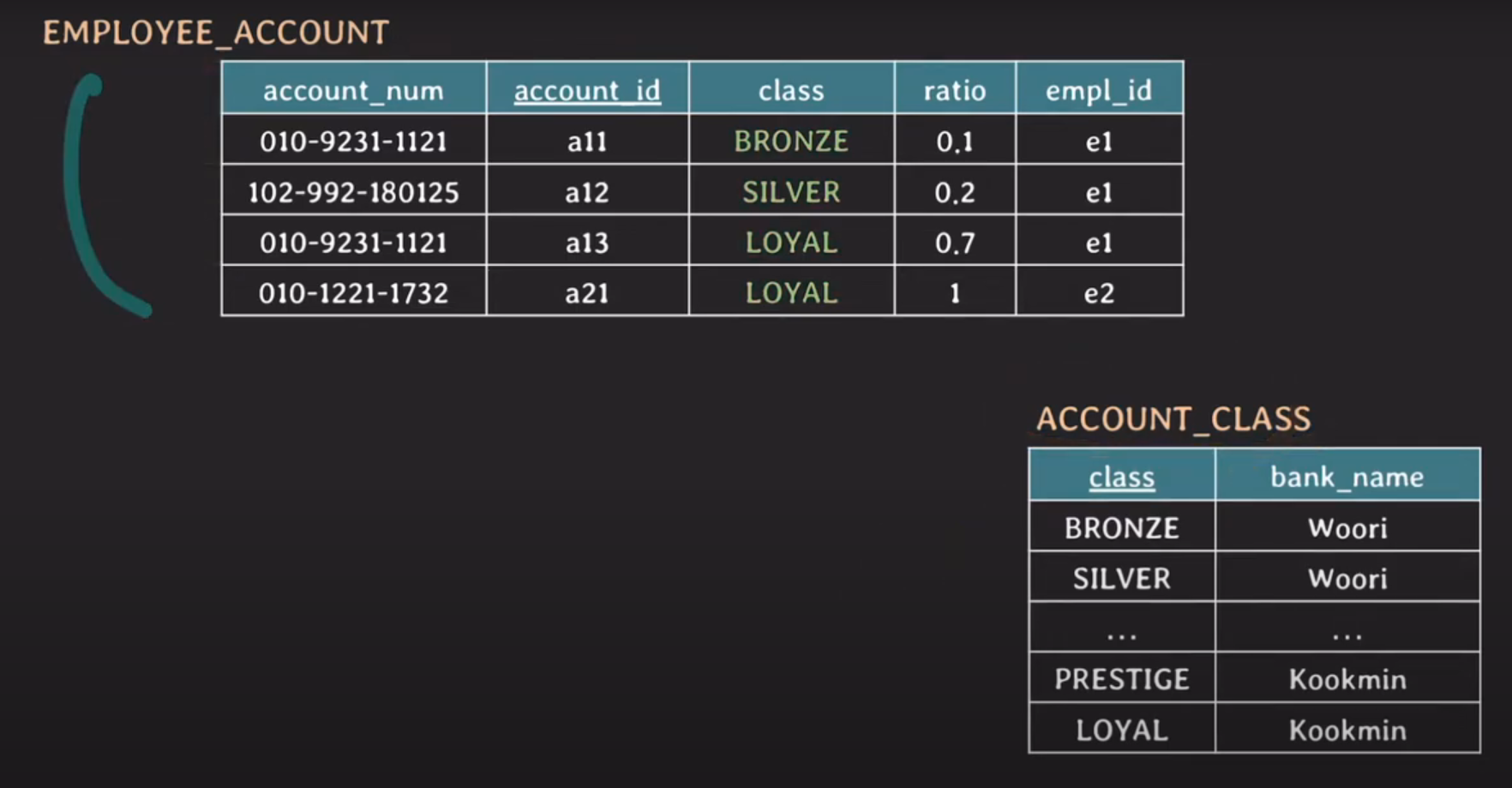
BFNF: 모든 유효한 non-trivial FD X → Y는 X가 super key여야 한다

bank_name : not super key
bank_name & class: bank_name → class (non trivial FD)
해당 FD는 BCNF 대상이다.
BCNF 이후
Denormalization (역 정규화)
데이터베이스 설계에서 성능을 개선하기 위해 정규화된 데이터 구조를 일부러 해제하는 과정을 말한다.
이를 통해 데이터 중복을 허용하고, 데이터 조회 시 필요한 조인을 줄이거나 제거하여 읽기 성능을 높이는 것이 주요 목적이다.
DB를 설계할 때 과도한 조인과 중복 데이터 최소화 사이에서 적정 수준을 잘 선택할 필요가 있다
'DataBase' 카테고리의 다른 글
| [DB] 파티셔닝, 샤딩, 레플리케이션 (0) | 2024.11.16 |
|---|---|
| [DB] B tree 전체 정리 (0) | 2024.11.15 |
| [DB] functional dependency 함수 종속 (4) | 2024.11.15 |
| [DB] 테이블 설계의 중요성 (2) | 2024.11.14 |
| [WINDOW] PostgreSQL 설치 (0) | 2024.09.03 |



