참고 자료
인덱스 유무에 따른 성능 차이

현재 쿼리는 CUSTOMER 테이블에서 first_name 이 'Minsoo'인 튜플을 찾는 예제이다.
first_name에 index가 걸려있지 않다면?
full scan(=table scan)으로 찾아야 한다 이는 O(N)이 걸린다.
first_name에 index가 걸려있다면?
full scan 보다 더 빨리 찾을 수 있다.
O(logN): B-tree based index
Index를 쓰는 이유
특정 조건을 만족하는 튜플(들)을 빠르게 조회하기 위해
빠르게 정렬(order by)하거나 그룹핑(group by)하기 위해
이미 생성된 테이블에 Index를 거는 문법
테이블 생성
create table team (
id int primary key,
team_name varchar(30) not null
);
create table player (
id int primary key,
name varchar(20) not null,
team_id int,
backnumber int not null,
foreign key (team_id) references team(id) on delete set null
);
ALTER TABLE player
CHANGE COLUMN name player_name varchar(20) not null;
Index를 적용해서 빠르게 실행하고 싶은 쿼리 1
SELECT * FROM player WHERE player_name = 'Sonny';player_name은 not unique 하다
Index 적용1
CREATE INDEX player_name_idx ON player (player_name);
Index를 적용해서 빠르게 실행하고 싶은 쿼리 2
SELECT * FROM player WHERE team_id = 105 and backnumber = 7;
team_id and backnumber 조합은 unique 하다
여러 팀에서 등번호는 겹칠 수 있지만 각 팀에 등번호는 고유하기 때문이다.
Index 적용2
CREATE UNIQUE INDEX team_id_backnumber_idx ON player (team_id, backnumber);
이렇게 유니크하게 식별할 수 있는 컬럼에 대한 인덱스는 앞에 UNIQUE 키워드를 붙인다.
테이블을 생성과 동시에 Index를 거는 문법
먼저 Player 테이블 삭제
DROP TABLE PLAYER;
Player 테이블 생성 + INDEX 추가
CREATE TABLE player (
id INT primary key,
player_name varchar(20) NOT NULL,
team_id INT,
backnumber INT,
INDEX player_name_idx (player_name),
UNIQUE INDEX team_id_backnumber_idx (team_id, backnumber),
foreign key (team_id) references team(id) on delete set null
);INDEX 이름은 생략이 가능하다. (자동으로 생성)
마찬가지로 UNIQUE하게 식별이 가능하면 UNIQUE 키워드를 붙인다.
2개 이상의 attributes 구성된 INDEX
composite index
multicolumn index
RDBMS에서 자동으로 PRIMARY KEY는 INDEX 생성을 한다.
Index 조회
SHOW INDEX FROM player;
B 트리 기반 인덱스 동작 방식

INDEX(a)는 a에 대한 값을 정렬된 순서로 저장된다.
또한 포인터를 가진다.
포인터는 Members 테이블의 튜플을 가리키게 된다.

WHERE a = 9;
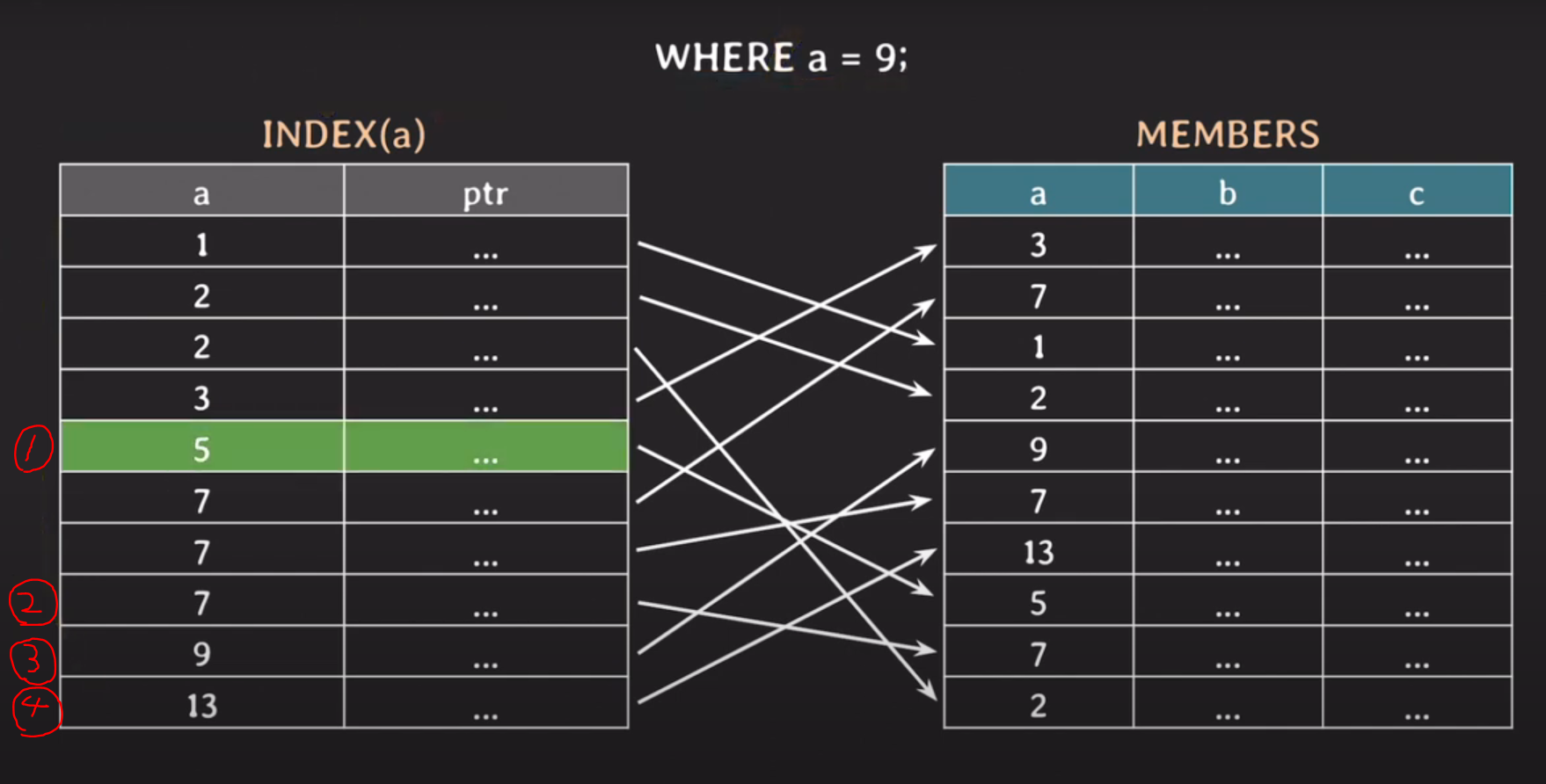
이분 탐색은 1번 2번 3번 4번을 순서로 찾는다.
이렇게 탐색이 가능한 이유는 INDEX가 a를 기준으로 오름차순 정렬이 되어있어서 가능하다.
1)
탐색 범위는 전체이다. 시작: 0(index) 끝: 값 13에 해당하는 인덱스
중간인 5를 찾는다.
WHERE 절에 걸린 9는 5보다 크니까 탐색 시작 범위를 현재 인덱스 + 1로 바꾼다.
2)
탐색 범위는 7 ~ 13 이다.
7 ~ 13 중간인 7을 찾았다.
WHERE 절에 걸린 9는 7보다 크니까 탐색 시작 범위를 현재 인덱스 + 1로 바꾼다.
3)
탐색 범위는 9 ~ 13 이다.
9 ~ 13 중간인 9를 찾았다.
WHERE 절에 걸린 9는 현재 인덱스의 9와 동일하다.
4)
현재 인덱스는 유니크한 인덱스가 아니다.
그래서 다음 3)에서 찾은 인덱스의 다음 인덱스의 값을 확인하지만 다음 인덱스의 값은 13이니 WHERE 절에 맞지 않아 종료한다.
이를 통해서 만약 유니크한 인덱스가 아니고 값의 중복이 심하다면 최악의 경우 마치 full scan의 시간 복잡도와 유사하겠다를 알 수 있다.
WHERE a = 7 AND B = 95;

동작 방식
이분 탐색을 통해서 A(INDEX)에서 7에 해당하는 값을 찾고
B 조건이 만족하는지 실제 테이블의 튜플로 접근해서 B값을 비교한다.
또한 a가 not unique INDEX이기 때문에 7 앞뒤로 추가적인 탐색을 한다.
물론 정렬이 되어있어서 7이 아닌 값을 확인하면 해당 탐색은 멈춘다.
즉, a = 7에 대한 튜플을 full scan 한다.
composite INDEX 활용

(a, b) composite INDEX 생성
그렇다면 정렬 순서는? CREATE INDEX(a,b)
a를 기준으로 오름차순 정렬하는데 a가 같다면 b를 기준으로 오름차순 정렬
해당 order를 통해서 INDEX(a,b)를 정렬한다.
똑같이 이분 탐색을 활용할 수 있다.
B 트리 기반 인덱스 이해 확인 예제

총 3개의 INDEX가 존재하고 2개의 쿼리를 실행했을 때 각 쿼리는 어떤 INDEX를 사용할까?
SELECT * FROM player WHERE team_id = 110;
team_id, backnumber 2개의 컬럼을 가지는 composite index를 사용한다.
team_id를 기준으로 정렬된 상태이기 때문에 composite index지만 빠르게 서칭이 가능하다.
SELECT * FROM player WHERE team_id = 110 AND backnumber = 7;
team_id, backnumber 2개의 컬럼을 가지는 composite index를 사용한다.

INDEX는 그대로고 추가적으로 2개의 쿼리를 실행한다고 가정 어떤 INDEX를 사용하고 성능은 어떨까?
SELECT * FROM player WHERE backnumber = 7;
team_id, backnumber 2개의 컬럼을 가지는 composite index를 사용한다.
성능은 full scan과 비슷하게 나온다.
해당 composite index는 team_id를 기준으로 정렬되고 같으면 backnumber를 기준으로 오름차순 정렬이기 때문에
backnumber 기준으로 보면 사실상 정렬이 안된 상태이다.
SELECT * FROM player WHERE team_id = 110 OR backnumber = 7;
team_id, backnumber 2개의 컬럼을 가지는 composite index를 사용한다.
성능은 full scan과 비슷하게 나온다.
team_id에 해당하는 튜플은 빠르게 찾을 수 있지만 추가적으로 backnumber = 7인 튜플도 찾아야 하기 때문에
이전 예제인 WHERE backnumber = 7; 똑같이 backnumber 기준으로는 정렬이 안된 상태이기 때문에 full scan과 비슷하다.
정리
사용되는 query에 맞춰서 적절하게 index를 걸어줘야 query가 빠르게 처리될 수 있다
실제 쿼리가 어떤 INDEX 사용하는지 확인하기 (EXPLAIN)
SHOW INDEX FROM player;
인덱스 총 3개
id(PK), (team_id, backnumber), (player_name)
EXPLAIN SELECT * FROM PLAYER WHERE TEAM_ID = 10;
team_id, backnumber composite 인덱스를 사용한다.
EXPLAIN SELECT * FROM PLAYER WHERE BACKNUMBER = 7;
키 사용을 하지 않는다
옵티마이저(optimizer)
이런 INDEX 선택은 optimizer가 알아서 적절하게 한다.
가끔 쿼리의 성능이 안 나와서 EXPLAIN으로 확인했더니 이상한 INDEX를 선택해서 사용하고 있을 수 있다.
이럴 때 개발자가 직접 특정 인덱스를 지정할 수 있다.
물론 이렇게 지정하고 나서 성능 테스트는 필수다
특정 인덱스를 사용하도록 명시하기
USE INDEX
SELECT * FROM PLAYER USE INDEX (team_id_backnumber_idx)
WHERE team_id = 1 AND backnumber = 10;
USE INDEX는 권장 사항이다.
즉, USE INDEX 사용이 100% 명시한 INDEX를 옵티마이저가 사용하는 걸 보장하지 않는다.
FORCE INDEX
SELECT * FROM PLAYER FORCE INDEX (team_id_backnumber_idx)
WHERE team_id = 1 AND backnumber = 10;
옵티마이저는 FORCE INDEX로 지정된 INDEX로 데이터를 가져오지 못한다면 full scan을 통해서 가져오고
아니라면 지정된 INDEX를 통해 가져온다.
IGNORE INDEX
SELECT * FROM PLAYER IGNORE INDEX (team_id_backnumber_idx)
WHERE team_id = 1 AND backnumber = 10;특정 인덱스를 사용하지 않도록 지시
인덱스는 막 만들어도 괜찮을까?
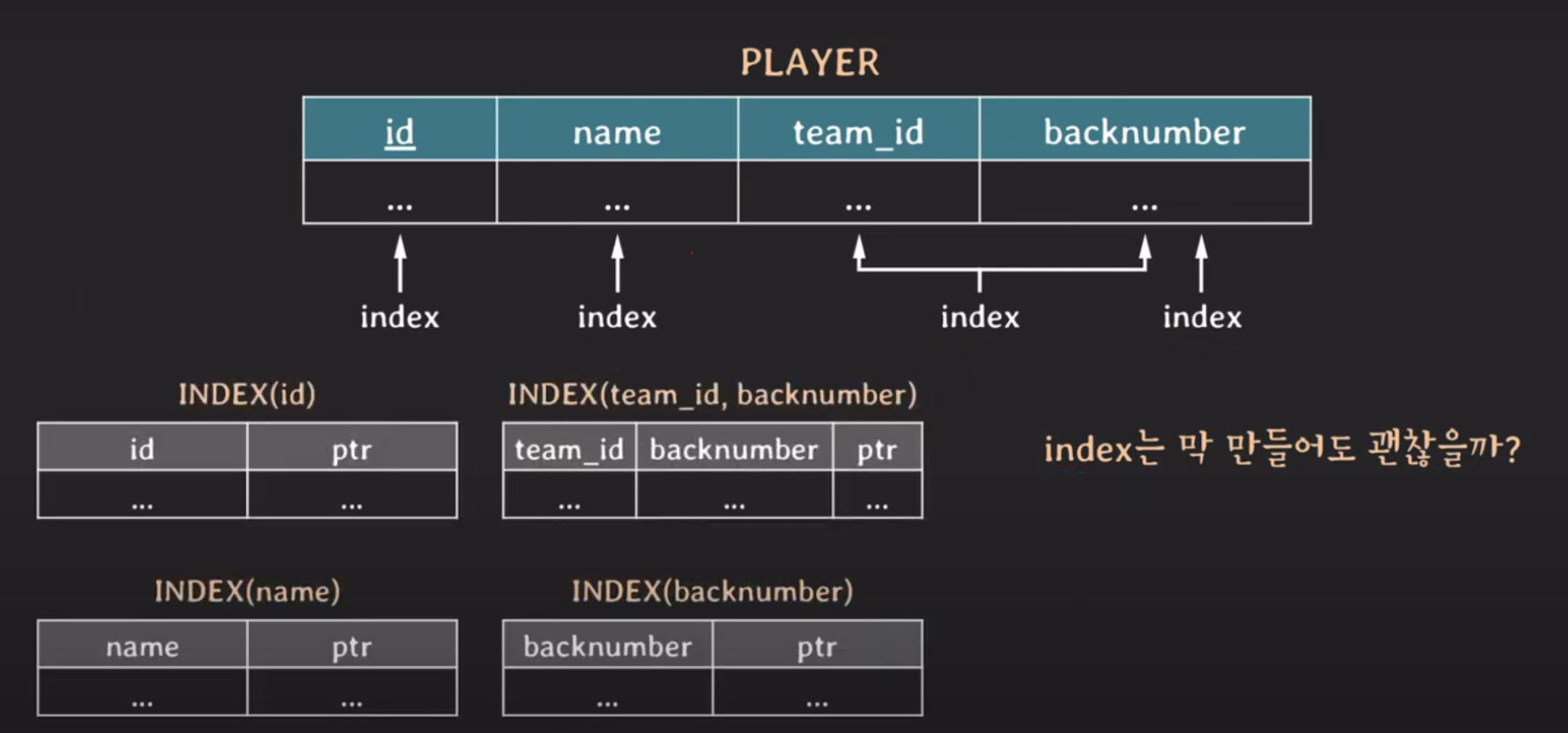
INDEX를 생성하면 각 INDEX마다 공간이 생성된다.
즉, 실제 데이터를 저장하는 공간 이외에 INDEX를 위한 부가적인 공간이 생기는 것이다.
2가지 관점
TABLE에 write할 때마다 index(insert update delete)도 변경 발생
즉, 오버헤드가 발생한다.
추가적인 저장 공간 차지
결론
불필요한 INDEX를 만들지 말자
ex) INDEX(team_id, backnumber) 인덱스가 존재하는데 INDEX(team_id)를 생성할 이유는 없다.
커버링 인덱스 Covering Index

INDEX(team_id, backnumber)가 있을 때
해당 쿼리문은 INDEX에 존재하는 데이터만으로 반환이 가능하다.
즉, 실제 데이터가 있는 테이블에 접근할 필요가 없다.
Covering Index
조회하는 attribute(s)를 index가 모두 cover할 때
조회 성능이 더 빠름
Hash Index
hash table을 이용하여 index를 구현
시간복잡도 O(1)의 성능
rehashing에 대한 부담
equality(!= , = ) 비교만 가능, range( >, >=) 비교 불가능
multicolumn index의 경우 전체 attributes에 대한 조회만 가능
Full scan이 더 좋은 경우
table에 데이터가 조금 있을 때 (몇 십, 몇 백건)
조회하려는 데이터가 테이블의 상당 부분을 차지할 때

CUSTOMER 테이블에 회원 숫자가 100만이 넘는다고 가정
SK를 사용하는 회원은 테이블에 상당 부분을 차지한다.
이런 경우에 Full scan이 더 좋다.
이런 full scan or index 활용은 optimizer 가 결정한다.
그 외
order by / group by에도 index가 사용될 수 있다.
foreign key에는 index가 자동으로 생성되지 않을 수 있다 (MySQL은 자동 생성)
이미 데이터가 몇 백만 건 이상 있는 테이블에 인덱스를 생성하는 경우 시간이 몇 분 이상 소요될 수 있고 DB 성능에 안좋은 영향을 줄 수 있다
'DataBase > MySQL' 카테고리의 다른 글
| [MySQL] DBCP 개념, 설정 (0) | 2024.11.16 |
|---|---|
| [MySQL] MVCC(Multi Version Concurrency Control) (3) | 2024.11.14 |
| [MySQL] Lock을 활용한 concurrency control (2PL) (1) | 2024.11.14 |
| [MySQL] 트랜잭션 격리 레벨 (6) | 2024.11.14 |
| [MySQL] concurrency control 기초2 (recoverability) (1) | 2024.11.13 |



