참고 자료
stored procedure?
Stored Procedure는 여러 개의 SQL 문을 모아 놓은 하나의 작업 단위로, 특정 작업을 수행하기 위해 데이터베이스에 저장된다.
반환값이 없거나 1개 이상도 가능하다. OUT 파라미터로 설정
stored function은 무조건 1개를 반환
stored procedure 예제1 (IN, OUT)
두 정수의 곱셈 결과를 가져오는 프로시저를 작성하자
프로시저 생성
DROP PROCEDURE IF EXISTS product;
delimiter $$
CREATE PROCEDURE product(IN a int, In b int, OUT result int)
BEGIN
SET result = a * b;
END
$$
delimiter ;파라미터에 IN, OUT 생략하면 기본적으로 IN으로 동작한다.
프로시저 사용
call product(5, 7, @result);
select @result;
stored procedure 예제2 (INOUT)
두 정수를 맞바꾸는 프로시저를 작성하자
프로시저 swap 생성
DROP PROCEDURE IF EXISTS swap;
delimiter $$
CREATE PROCEDURE swap(INOUT a int, INOUT b int)
BEGIN
SET @temp = a;
SET a = b;
SET b = @temp;
END
$$
delimiter ;파라미터에 INOUT을 사용하면 입력 매개변수이자 동시에 반환 변수이다.
프로시저 swap 사용
SET @a = 5, @b = 7;
call swap(@a, @b);
select @a, @b;
stored procedure 예제3
각 부서별 평균 연봉을 가져오는 프로시저를 작성하자
프로시저 get_dept_avg_salary 생성
DROP PROCEDURE IF EXISTS get_dept_avg_salary;
delimiter ^^
CREATE PROCEDURE get_dept_avg_salary()
BEGIN
SELECT dept_id, AVG(salary)
FROM employee
group by dept_id;
END
^^
delimiter ;
MySQL에서는 특정 반환 변수를 지정하지 않아도 SELECT에 해당하는 값을 반환한다.
프로시저 get_dept_avg_salary 실행
call get_dept_avg_salary();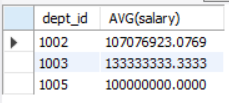
프로시저 검증
SELECT dept_id, (SUM(salary) / count(*)) as 'AVG(salary)'
FROM employee
group by dept_id;
그룹함수(aggregation function) sum, count를 사용해서 프로시저가 잘 동작하는지 체크했다.

stored procedure 예제4
WHEN: 사용자가 프로필 닉네임을 바꾸면
DO: 이전 닉네임을 로그에 저장하고 새 닉네임으로 업데이트하는 프로시저를 작성하자
사전 작업 users 테이블, nickname_logs 테이블 생성
CREATE TABLE users (
id int primary key auto_increment,
nickname varchar(20) not null
);
CREATE TABLE nickname_logs (
id int primary key auto_increment,
users_id int,
prev_nickname varchar(20) not null,
until datetime,
foreign key (users_id) references users(id) on delete cascade
);
프로시저 생성 change_nickname
delimiter ^^
CREATE PROCEDURE change_nickname(IN user_id INT, IN new_nick varchar(20))
BEGIN
INSERT INTO nickname_logs (users_id, prev_nickname, until)
(select id, nickname, now() from users where id = user_id);
update users set nickname = new_nick where id = user_id;
END
^^
delimiter ;
테스트
insert into users (nickname) values('jewoo');
select * from users;
call change_nickname(1, 'zeus');
call change_nickname(1, 'zeus1212');
조인해서 출력하기
select u.id, u.nickname as current_name, n.prev_nickname, n.until
from users u join nickname_logs n on u.id = n.users_id;
stored procedure vs stored function
| STORED PROCEDURE | STORED FUNCTION | |
| CREATE 문법 | CREATE PROCEDURE PR_NAME | CREATE FUNCTION FUNC_NAME |
| return 키워드로 반환 | 불가능 (SQL server는 상태코드 반환용으로 가능) |
가능 (MySQL, SQL server는 값 반환하려면 필수) |
| 파라미터로 값(들)반환 | 가능 | 일부 가능 (oracle 가능하나 권장 x, postgreSQL 가능) |
| 값 반환 필수? | 필수 X | 필수 O |
| SQL statement 호출 | 불가능 | 가능 |
| transaction 사용 | 가능 | 불가능 |
| 주된 사용 목적 | 비즈니스 로직(business logic) | 연산(computation) |
Three-tier Architecture
오늘날의 IT 회사들은 일반적으로 client-server architecture 한 종류인
three-tier architecture 모델로 서비스를 개발한다
Presentation tier: 사용자에게 보여지는 부분을 담당하는 tier
Logic tier: 서비스와 관련된 기능과 정책 등등 비즈니스 로직을 담당하는 tier
Data tier: 데이터를 저장하고 관리하고 제공하는 역할을 하는 tier

Stored Procedure를 사용한다는 것은?
데이터 티어에서 비즈니스 로직을 사용한다는 것
Stored Procedure 장점
1. application에 transparent 하다
Java Spring application이 4개의 서버로 운영되고 1대의 MySQL 서버로 운영된다고 가정
만약 비즈니스 로직이 수정되어서 재배포 한다고 하면
동시에 자바 스프링 애플리케이션을 내리고 수정해서 재배포 하는 게 아닌 1대의 서버씩 내리고 업데이트하는 방향으로 진행할 것이다. 근데 비즈니스 로직이 데이터 티어인 DB 즉 stored procedure에 있고 각 애플리케이션은 호출만 한다고 하면? db에 procedure의 이름이 바뀌는 게 아니라면 body(BEGIN - END)부분만 수정하면 끝이다.
즉 이런점이 application에 transparent 하다고 설명할 수 있다.
2. network traffic을 줄여서 응답 속도를 향상시킬 수 있다.
기존 자바 스프링의 애플리케이션에 어떤 비즈니스 로직에서
select, insert, update 3개의 쿼리가 사용된다고 가정
그럼 자바 스프링 애플리케이션 서버와 db 서버는 select 에서 1번 insert에서 1번 update에서 1번
총 3번의 네트워크를 탄다
하지만 비즈니스 로직인 stored procedure를 사용하면 db와 자바 스프링 애플리케이션의 통신은 1번이면 끝난다.
3. 여러 서비스에서 재사용 가능하다
서비스 A: 자바 스프링 기반
서비스 B: 파이썬 장고 기반
서비스 C: 노드 js 기반
이렇게 3개의 서비스가 있을 때 만약 동일한 비즈니스 로직을 각각의 서비스로 구현하는 방법은 효율이 떨어진다.
하지만 stored procedure로 비즈니스 로직을 구현하면 각 서비스는 호출만 하면 끝이다.
Stored Procedure 단점 & 실무에서 거의 사용하지 않는 이유
1. stored procedure를 쓰게 되면 유지 관리 보수 비용이 커진다
1-1 비즈니스 로직의 이해를 위해서 logic 티어의 소스 코드와 db 코드를 번갈아가면서 확인을 해야 한다
1-2개발자들이 로직 티어의 언어/프레임워크 뿐만 아니라 db의 stored procedure를 학습하는 비용이 필요하다
1-3 버전 관리가 어렵다 db, 애플리케이션 서버 모두 관리 해야 한다
2. DB 서버를 추가하는 것은 간단한 작업이 아니다
트래픽 부하가 늘어났을 때 애플리케이션 서버의 서버 증설보다 DB 서버 증설은 어려운 작업이다.
데이터베이스의 원래 목적는 데이터 보관이다. 데이터를 복사해서 신규 서버에 넣어야 하는데 이 작업은 쉽지 않다.
3. stored procedure가 언제나 transparent인건 아니다
만약 stored procedure의 이름이 바뀌면 애플리케이션 서버의 stored procedure 호출 소스 코드 또한 전부 변경된다.
4. transparent가 무조건 좋은건 아니다
만약 stored procedure를 변경했는데 문제가 생기면 stored procedure의 오류가 롤백 될 때까지 모든 사용자가 피해를 본다.
하지만 애플리케이션 서버에 로직 변경으로 인한 문제가 생기면 해당 서버만 수정하면 된다.
보통 한 번의 모든 서버를 내렸다가 다시 배포하는 경우는 없다.
즉 미치는 영향력이 그만큼 크다
5. 로직 티어에서도 응답 속도를 향상 시킬 수 있다
stored procedure의 큰 장점은 네트워크 비용을 줄일 수 있다는 것이다
하지만 쿼리들이 순차적으로 처리할 필요가 없다면 로직티어에서 db로 비동기 방식을 사용해 처리하면 이전 쿼리에 대한 응답을 기다릴 필요 없이 처리하면 응답 속도를 향상시킬 수 있다
캐싱 또한 응답 속도를 향상시킬 수 있다
'DataBase > MySQL' 카테고리의 다른 글
| [MySQL] 트랜잭션과 ACID (0) | 2024.11.13 |
|---|---|
| [MySQL] 트리거 trigger (3) | 2024.11.12 |
| [MySQL] 스토어드 함수 stored function (1) | 2024.11.12 |
| [MySQL] RealMySQL 8.0 4.1: MySQL 엔진 아키텍처 (0) | 2024.11.11 |
| [MySQL] RealMySQL 8.0 3장: 사용자 및 권한 (0) | 2024.11.09 |



